
Simplify with Subsystems
 A major differentiator of the IBM i operating system is the use of subsystems to separate workloads, often for managing memory and optimizing performance. While those are still valid reasons for separating work into multiple subsystems, today’s large memory sizes and fast processors reduce the need to optimize performance in this way.
A major differentiator of the IBM i operating system is the use of subsystems to separate workloads, often for managing memory and optimizing performance. While those are still valid reasons for separating work into multiple subsystems, today’s large memory sizes and fast processors reduce the need to optimize performance in this way.
In this article, I’ll explain how subsystems can make today’s web-oriented application workloads much easier to manage.
Most Common Subsystem Configuration
In most shops I have worked with, most activity occurs in a single partition. These days, that activity often includes core business applications that are dependent on web servers and database server jobs.
Almost every shop I have worked with runs these jobs in their default subsystems: web servers in the QHTTPSVR subsystem, ODBC database server jobs in QUSRWRK, and SQL CLI server jobs (QSQSRVR) in QSYSWRK. I also see a lot of shops dependent upon remote command server jobs and data queue server jobs, also running in QUSRWRK. This configuration is not optimal, but it all runs just fine. Usually.
This configuration is not optimal, but it all runs just fine. Usually.
With this default configuration, however, it can be very difficult to answer the following types of questions:
- What application is driving the paging in *BASE pool?
- What application is causing the CPU to be consumed?
- Why do I have CPU queueing?
- How do I capture SQL errors that I know are coming from Application X when I have hundreds of database server jobs supporting many applications?
A Better Subsystem Configuration
The solution to answering these questions is to separate server jobs for different applications into different subsystems. You don’t have to go down the path of adding additional shared pools—you can let jobs run in the memory pools they run in today. The simple act of separating jobs into a subsystem per application can go a very long way to better understanding, managing, and troubleshooting your applications.
I love this method of subsystems arrangement because grouping applications into their own subsystem simplifies the management of your system.
Real-World Example
Recently, I was asked to do a performance study for a client. Their system, as with many I review, used the default subsystems as shipped by IBM. The client had recently moved from Zend Server PHP to Seiden PHP+.
Upon reviewing their QHTTPSVR subsystem, I saw many different web server instances, most of which were non-critical web utilities. Their primary PHP application used the classic ibm_db2 PHP extension, so all the database work was running in QSQSRVR jobs in QSYSWRK, but this workload was mixed in with other SQL CLI access.
In reviewing performance characteristics, it was almost impossible to differentiate and assess the resources used by the PHP web application itself.
I suggested that all work for this PHP application be isolated into a single subsystem—the web server and its associated SQL CLI jobs. This configuration is not difficult to set up.
How to Isolate an Application’s Server Jobs
I’ll review each of these key steps below:
- Create the subsystem
- Modify the web server configuration to use this subsystem
- Modify the web server to connect to jobs in the new subsystem
1. Create the Subsystem
- Create the subsystem description in which the application will run. It is easiest to start by duplicating the QHTTPSVR subsystem description, since this is where the PHP web server currently runs. This subsystem needs a job queue and a job queue entry. The routing entry should be the same as the one used in the QHTTPSVR subsystem.
- Add a prestart job entry for QSQSRVR jobs to this subsystem description. The command below replicates the prestart job entry so it is similar to the one in QSYSWRK. Note the JOB parameter; this parameter overrides the job name to make it easy to see that these jobs are handling SQL CLI requests. You can use whatever job name you wish. I recommend overriding the default job name to eliminate any confusion with other work in QSQSRVR jobs. It also makes it MUCH easier to review performance data in the performance data investigator, as there are numerous charts to display information by job name or generic job name.
ADDPJE SBSD(LIBNAME/SEIDENSBS) PGM(QSYS/QSQSRVR) STRJOBS(*YES) INLJOBS(100) THRESHOLD(2) ADLJOBS(2) MAXJOBS(*NOMAX) JOB(SEIDENCLI) JOBD(QGPL/QDFTSVR) MAXUSE(200) CLS(QSYS/QSYSCLS20)
The prestart job entry parameters for INLJOBS, THRESHOLD, and ADLJOBS should be set up to reflect the workload. The references at the end of this article includes a link to the article Prestart Job Considerations for more information on prestart job tuning. - When you create a new subsystem, you must ensure the system startup program is updated to start this subsystem at IPL (or whatever procedures you have in place for starting subsystems). Note, however, that if the web server instance is automatically started, the web server startup processing will start the subsystem if it is not active.
- Create a job description that is similar to the job description used by the web server jobs in the QHTTPSVR subsystem, which by default is QZHBHTTP in the QHTTPSVR library. The job description needs to specify the job queue and routing data used in your new subsystem. I highly recommend LOG(4 0 *NOLIST). Many of the parameters rely on system value settings. You may want to check the following system values:
- QLOGOUTPUT. The default is *JOBEND, but *JOBLOGSVR is a much better setting.
- QJOBMSGQSZ. Many shops set this to the largest size of 64Mb; 16MB or 8MB is much better to avoid overcommitting disk space for a lot of very large job logs in the event of an unexpected issue.
- QJOBMSGQFL. I often see this set to *NOWRAP or *PRTWRAP. I like *WRAP the best. If the job message queue is wrapping, do you really want all those spooled job logs? If you do have a need for wrapping job logs to be spooled, specify *PRTWRAP on the job descriptions for the critical jobs, but set the system value to *WRAP.
2. Add the subsystem configuration directives to the HTTP server configuration
There is no GUI interface to specify the subsystem in which an HTTP server should run. Rather, you must edit the httpd.conf file for that HTTP instance. This configuration file is found in the IFS in the /www/instance/conf directory for the web server. You can edit the file directly, or by using the IBM i Web Administration GUI.
The following directives are used when routing an HTTP Server instance to its own subsystem. These should be self-explanatory.
- HTTPRoutingData – specifies the user defined routing data for HTTP server jobs (HTTPWWW).
- HTTPStartJobDesc – specifies the job description that defines how HTTP server jobs should be run. This is the job description you created for the work in this subsystem.
- HTTPStartJobQueue – specifies the created job queue to which the HTTP server jobs will be submitted. This is the job queue created for this subsystem.
- HTTPSubsystemDesc – specifies the name of the subsystem you created. This is where the HTTP server runs in.
3. Route the SQL CLI requests to the new subsystem
Depending upon your environment and application, there are several ways to route the SQL CLI requests (QSQSRVR jobs) to your new subsystem.
For PHP applications, the ibm_db2 configuration option of ibm_db2.i5_servermode_subsystem can be used to specify the subsystem in which the connection will be made to the QSQSRVR jobs. A value of *SAME means to run in the subsystem of the requester. Simply add this configuration option to the ibm_db2.ini file. This configuration file, 99-ibm_db2.ini, is found in the IFS, either under /QOpenSys/etc/php/conf.d or in /www/instance/phpconf/conf.d. (With Seiden PHP+, the Display Site command (dspsite instance) will tell you the location of your .ini files.)
The subsystem directive has the format as follows:
ibm_db2.i5_servermode_subsystem=*SAME
Using *SAME will result in all jobs for that PHP application running in the web server subsystem, including the HTTP server jobs, the PHP helper jobs, and the SQL CLI server jobs. Using this approach makes it very easy to understand the resources consumed by that application. Because we used the JOB parameter on the prestart job entry, these SQL CLI server jobs will not be named QSQSRVR, but rather have the job name you specified.
This configuration directive also supports specifying a specific name of the subsystem in which the SQL CLI jobs should run, rather than the same subsystem as the web jobs. You can then place those jobs in their own isolated subsystem if desired.
Outside of PHP, if you want to route QSQSRVR jobs to subsystems other than QSYSWRK, there are a variety of ways to do it. Personally, I hate that the QSQSRVR jobs are in QSYSWRK by default—they are doing user application work and have no business in the system subsystem! You can easily move all QSQSRVR jobs out of QSYSWRK and into their own subsystem with an environment variable. It’s beyond the scope of this article to review all the ways to route SQL CLI requests, so see the article QSQSRVR Job Considerations listed in the references for more information.
A Thing of Beauty
Once you have your new subsystem in place with the all the work for one application happening in one subsystem, reviewing the resources used by that subsystem is easy. Using New Nav, go into Investigate Data with the Collection Services content package selected. Select the library and collection you want to display, then type Waits by Subsystem in the perspective path column filter. Click on the Waits by Subsystem link to display that chart with the desired performance collection. You can see, with just a glance, how the resources used by your new subsystem compares to the other work on your system. (Note that, depending upon your Collection Services data, wait by subsystem may take a while to display).
The screen capture below shows the new SEIDENSBS as the third busiest on this partition. At the default settings we could not know this, as the work would be mixed in with other work in QHTTPSVR and QSYSWRK subsystems.

Waits by Subsystem
In this next screen capture, we selected SEIDENSBS and took the drill-down action of “Waits for one Subsystem.” This shows the run/wait signature for the SEIDENSBS over the course of the day. From this, we can see how the application runs during core business hours. In general, the application is CPU bound, as shown by the red bars. However, there are a few periods of time where we see orange bars, which reflect disk page fault time, and some purple bars, which reflect CPU Queuing time.
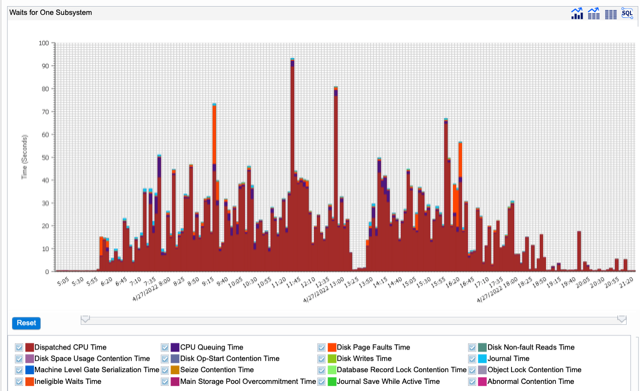
Waits for One Subsystem
We can select an interval of time to investigate the top contributors. For example, if we select the bar with the purple CPU queueing time at approximately 7:35AM, and take the drill down action of “Waits by Job or Task”, we can review the top contributors of CPU queueing in that interval. In this case, we see two sets of jobs, a PHP job and an SQL CLI job. The CPU queueing is quite likely due to fast interactions between the two jobs handing the work request.

Waits for Job
I want to add one final recommendation. Take advantage of the client special registers in your application. If you specify these on the client side, it can make understanding work in the database server jobs much easier. The article Client Special Registers are Special listed in the references has more information about client special registers.
References
The following iCan blog posts provide additional information on the topics covered in this article.
Run an HTTP Server in its Own Subsystem
Leave a Reply
Want to join the discussion?Feel free to contribute!